Archive for 2015
Logical Agent
- มีฐานความรู้ของตนซึ่งเป็นชุดของประโยคที่แสดงออกในความรู้ภาษาเป็นตัวแทน
- ตัวแทนตรรกะสามารถเพิ่มประโยคใหม่เพื่อ KB รวมทั้งใช้ในการตอบคำถามสรุปมาจาก KB รับประกันได้ว่าจะถูกต้องหาก KB ที่ถูกต้อง
- อนุมาน: อันเกิดประโยคใหม่จากที่มีอยู่
Ex: โจอี้เป็นสุนัข; สุนัขเป็นสัตว์; โจอี้จึงเป็นสัตว์
โจทย์
Propositions: assertions, statements
- เป็นเรื่องที่สามารถเป็นจริงหรือเท็จ
- ตัวอักษรเป็นทั้งสัญลักษณ์หรือสัญลักษณ์เชิงลบ
Ex: P, ~Q
Ex:“โจอี้เป็นสุนัข” P
“สุนัขเป็นสัตว์” Q
“ฉันมีสองแอปเปิ้ล” S
ตัวดำเนินการทางตรรกศาสตร์
~ not (negation, sometimes written ~) ปฎิเสธ
Λ and (conjunction)ตัวเชื่อม
V or (disjunction)
↔ if and only if ถ้าแล้ว
ลำดับความสำคัญ (สูงสุดไปต่ำสุด):~, Λ, V, , ↔

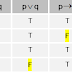
ถูกต้อง(Valid)
- คำสั่งที่ถูกต้อง (หรือเราบอกว่าเป็นคำสั่งซ้ำซาก) ถ้าหากคำสั่งที่เป็นความจริง เพื่อทดแทนที่เป็นไปได้ของตัวแปรของพวกเขา
- Ex: (พีวีพี ~) เป็นซ้ำซาก
p ~p p V ~p
T F T
F T T
Unsatisfiable
- คำสั่งเป็น unsatisfiable (หรือเราบอกว่าคำสั่งที่เป็นความขัดแย้ง) ถ้าหากว่าคำสั่งที่เป็นเท็จเพื่อทดแทนที่เป็นไปได้ใด ๆตัวแปรของพวกเขา
- Ex: (P Λ ~ P) เป็นความขัดแย้ง
p ~p p Λ ~p
T F F
F T F
Satisfiable(ความพอใจ)
คำสั่งคือ satisfiable (พอใจ)ถ้าหากว่า
คำสั่งที่เป็นจริงสำหรับอย่างน้อยหนึ่งที่เป็นไปได้
ทดแทนของตัวแปรของพวกเขา
Ex: ทั้งสอง (pΛ q) (p V q) มีความพอใจ
p q p Λ q p V q
T T T T
T F F T
F T F T
F F F F
ประพจน์ตรรกะสมมูล (Logical equivalent)
De Morgan’s Laws (กฎของมอร์แกนเดอ)
~(p Λ q) ≡ ~p V ~q
~(p V q) ≡ ~p Λ ~q
Transformation(การเปลี่ยนแปลง)
p q ≡ ~p V q
Contrapositive
p q ≡ ~q ~p
Propositional Logic(ตรรกะของประพจน์)
“โจอี้เป็นสุนัข” P
“สุนัขเป็นสัตว์” Q
“โจอี้เป็นสัตว์” R
“โจอี้เป็นสุนัข; สุนัขเป็นสัตว์; โจอี้จึงเป็นสัตว์”
(P Λ Q) --> R
ดังนั้นวิธีการที่สามารถประโยคตรรกะเหล่านี้ช่วยให้เราแก้ปัญหา?
Entailment
Entailment: ประโยคจากเหตุผลดังต่อไปนี้อื่น
KB ╞ α
ฐานความรู้ของ KB ที่มีรายละเอียดαประโยคถ้าหากαเป็นความจริงในโลกทั้งหมดที่ KB ที่เป็นความจริง
Ex: x + y = 4 entails y + x = 4
Proof by contradiction(การพิสูจน์โดยข้อขัดแย้ง)
- α ╞ β iff (α Λ ~β) is unsatisfiable
- นั่นคือสมมติว่าเรารู้ว่าαเราสามารถพิสูจน์βโดยแสดงให้เห็นว่า (αΛ ~ β) ไม่สามารถเป็นจริง
- ในคำอื่น ๆ ที่เราพิสูจน์ได้ว่าเป็นความจริงβโดยแสดงให้เห็นว่าถ้าβเป็นเท็จก็จะขัดแย้งกับα
Example 1
Given
(P Λ ~R) “พีทอยู่ที่นี่ "และ" รอนไม่ได้อยู่ที่นี่” (1)
(~Q R) “หากควีนไม่อยู่ที่นี่แล้วรอนอยู่ที่นี่” (2)
ต้องการที่จะพิสูจน์
Q “ควีนอยู่ที่นี่” (3)
หลักฐานจากความขัดแย้ง จำเป็นที่จะต้องแสดงให้เห็นว่าทุกการรวมกันของค่าความจริง P, Q, R, ไม่มีใครทำให้ประโยคต่อไปนี้เป็นความจริง
(1) Λ (2) Λ ~(3)
(P Λ ~R) Λ (~Q R) Λ ~Q

- ? เราได้แสดงให้เห็นว่า
ไม่สามารถที่จะเป็นจริง และเรากำลังได้รับว่าทั้งสอง (1) และ(2) เป็นจริง
ดังนั้น ~ (3) ต้องเป็นเท็จซึ่ง ทำให้ (3) ความจริงที่เราอยากจะพิสูจน์
Example 2
Given
Q R (1)
~(R P) Q (2)
P V R (3)
ต้องการที่จะพิสูจน์
P V Q (4)
หลักฐานจากความขัดแย้ง จำเป็นที่จะต้องแสดงให้เห็นว่าประโยคต่อไปนี้ไม่สามารถเป็นจริง
(1) Λ (2) Λ (3) Λ ~(4)

- (1) Λ (2) Λ (3) Λ ~(4)มักจะเป็นเท็จและ(1), (2), (3)เป็นจริง ดังนั้น(4)ต้องเป็นจริงตามที่ต้องการ
Example 3
Given
Q R (1)
~(R P) Q (2)
P R (3)
ต้องการที่จะพิสูจน์
R (4)
หลักฐานจากความขัดแย้ง จำเป็นที่จะต้องแสดงให้เห็นว่าประโยคต่อไปนี้ไม่สามารถเป็นจริง
(1) Λ (2) Λ (3) Λ ~(4)

(1) Λ (2) Λ (3) Λ ~(4)
สามารถเป็นจริงหรือเท็จ เราไม่สามารถพิสูจน์ได้ว่าเป็นความจริง R
Conjunctive Normal Form
- ประโยคที่อยู่ในรูปแบบปกติที่เชื่อมต่อกัน (CNF) ถ้ามันจะแสดงเป็นร่วมของ disjunctions ของตัวอักษร
(literal1 V ... V literali) Λ ... Λ (literalj V ... V literalk)
- ประโยคของประพจน์ลอจิกทุกคนสามารถเป็นกลายเป็น CNF
- วิธีการเปลี่ยนประโยคเป็น CNF
- R ↔ (P V Q)
Resolution(ความละเอียด)
- มติที่จะใช้เวลาสองข้อ CNFและสร้างประโยคใหม่ที่มีตัวอักษรทั้งหมดของทั้งสองคำสั่งเดิมยกเว้นสองตัวอักษรเสริม
Ex: Given: (A V B) Λ (~B V C)
ผลลัพธ์: A V C
(A V B) Λ (~B V C)หมายถึงA V C (แต่ไม่ได้อยู่ในทางกลับกัน)


มี x บางอย่างเช่นว่าถ้ากินผักขม x คือ x
จะกลายเป็นที่แข็งแกร่ง
อดีตกิน (x, ผักโขม)? ที่แข็งแกร่ง (x)
- ? ไม่มีคำสั่งใหม่ที่สามารถเพิ่มที่ กรณี KB ไม่ตกทอดαหรือ
- ? การประยุกต์ใช้กฎความละเอียดที่มา ข้อที่ว่างเปล่าในกรณีที่ส่งผล KB α


ไม่มีคำสั่งที่ต้องทำ ความละเอียด--> ไม่สามารถที่จะ พิสูจน์ให้เห็นว่า R เป็นความจริง
First-Order Logic
- ปัญหาเกี่ยวกับลอจิกประพจน์: ไม่ที่แสดงออกพอ
- ในโลกที่ลอจิกประพจน์มีข้อเท็จจริงอยู่
- ในโลกครั้งแรกที่สั่งซื้อลอจิกมีข้อเท็จจริงอยู่วัตถุและความสัมพันธ์
- FOL เป็นที่แสดงออกมากขึ้น เราสามารถมีประโยคกับตัวแปรและฟังก์ชั่น
Universal Quantifier
"สำหรับทุกอย่าง ... "
Ex:
สำหรับ x ทุกคนถ้า x เป็นเด็ก x ชอบไอศครีม
เด็กขวาน (x)? ชอบ (x, ไอศครีม)
สำหรับ x ทุก x เป็นทั้งสีเหลืองหรือสีเขียว (หรือทั้งสอง)
Ax เหลือง (x) กรีน V (x)
Existential Quantifier(E)
อัตถิภาวปริมาณ
- "สำหรับบางคน ... " หรือ "มีอยู่ ... "
- Ex: มีเด็กบางคนที่ไม่ชอบผัก (E)
มี x บางอย่างเช่นว่าถ้ากินผักขม x คือ x
จะกลายเป็นที่แข็งแกร่ง
อดีตกิน (x, ผักโขม)? ที่แข็งแกร่ง (x)
Nested Quantifier
- ปริมาณที่ซ้อนกัน
- ทุกคนมีคนที่เขา / เธอชอบ
Ax Ey มนุษย์ (x) Λมนุษย์ (y) Λชอบ (x, y) ขวาน
- มีคนที่ทุกคนชอบคือ
Ax มนุษย์ (x) Λมนุษย์ (y) Λชอบ (x, y)
Negation
และการปฏิเสธ
- การเชื่อมต่อระหว่าง
ชอบขวาน (x, IceCream)
ขวาน ~ ~ ชอบ (x, IceCream)
อดีต ~ ชอบ (x, IceCream) ~
ทุกคนชอบไอศครีม
ไม่มีใครที่ไม่เป็น
- บางกฎ
ไม่ชอบไอศครีม
Ax ≡≡ E ~ ~ Ex x ขวาน
CNF in FOL
- วิธีการเปลี่ยนประโยคเป็น CNF


Resolution in FOL
- ในขณะที่ลอจิกประพจน์เพื่อที่จะใช้ความละเอียด FOL ต้องใช้ประโยคที่จะอยู่ใน CNF
- ความละเอียด: คล้ายกับผู้ที่อยู่ในลอจิกประพจน์ แต่มีตัวแปร / ทดแทนอย่างต่อเนื่อง
- ได้รับ Au, v, x, y
กิน (x, y)? ล่า (x, y)
ล่า (ยูวี) ~ ล่า (V, มึง) - ? ต้องการที่จะพิสูจน์
(1) ถ้าฉันกินคุณฉันล่าคุณ
(2) ถ้าฉันล่าคุณคุณไม่ล่าฉัน
น้ำหนัก ~ กิน (สิงโตน้ำหนัก) - ? นั่นคือพิสูจน์ว่า (1) Λ (2) Λ ~ (3) เป็น unsatisfiable
(3) มีสิงโตบางสิ่งบางอย่างที่ไม่ได้กิน
ตัวอย่างเครดิต: สเวนนิก


การตัดสินใจใช้ทฤษฎีเกม(Decision Making using Game Theory)
Games as Search Problems(เกมเป็นปัญหาค้นหา)

Minimax
- ได้รับต้นไม้เกมนี้กลยุทธ์ที่ดีที่สุดสามารถ กำหนดโดยการตรวจสอบค่าของ Minimax แต่ละโหนด
- minimax_value(s)
maxs’ є Successors(s) minimax_value(s’)if s is MAX
mins’ є Successors(s) minimax_value(s’) if s is MIN

คำนวณค่าminimaxจากด้านล่างขึ้น
- ค่าฟังก์ชั่นมินิแมกซ์) พบว่าผลของ MAX MIN สมมติว่ายังเล่นได้อย่างดีที่สุด
- ค่าฟังก์ชั่นมินิแมกซ์) พบว่าผลของ MAX กรณีเลวร้ายที่สุด; ว่ามีที่แม็กซ์อาจได้รับแม้จะเป็นผลดีกว่าถ้า MIN เล่นที่ไม่ได้อย่างดีที่สุด
- ปัญหาที่อาจเกิดขึ้น: จำนวนมากของโหนดในต้นไม้ค้นหา (ชี้แจงในการแยกปัจจัยและความลึก)
- แต่ก็เป็นไปได้ที่จะได้รับการแก้ปัญหาตรงเดียวกันโดยไม่ต้องมองหาที่โหนดในต้นไม้เกมทุก !!
Alpha-Beta Pruning
- จะช่วยให้การแก้ปัญหาเช่นเดียวกับมินิแมกซ์จะโดยไม่ได้มองที่โหนดในต้นไม้เกมทุก
- Prunesไปสาขาที่ไม่สามารถเป็นไปได้ มีอิทธิพลต่อการตัดสินใจครั้งสุดท้าย
- α: ค่าที่ต่ำกว่ามินิแมกซ์มุ่ง MAX
- β: ค่ามินิแมกซ์บนมุ่ง MIN



- ด้วยการตัดแต่งกิ่งα-βดูที่ 6 โหนด
- โดยไม่ต้องมีการตัดแต่งกิ่งα-βดูที่ 9 โหนด
- ยังคงมีการตัดแต่งกิ่งแม้จะมีα-βทำงานในเต็มรูปแบบต้นไม้ที่เป็นไปไม่ได้เกมมากที่สุดในโลกแห่งความจริงปัญหาที่เกิดขึ้น
หมากรุก
- กว่า 1,300 ปี
- เกมกระดานสองคนซึ่งจำลองการต่อสู้ระหว่างกองทัพทั้งสองฝ่ายตรงข้าม
- ผู้เล่นผลัดกันการย้ายหรือการจับ
- วัตถุประสงค์: เพื่อจับกษัตริย์ของฝ่ายตรงข้าม
- ตรวจสอบ: ผู้เล่น declares "ตรวจสอบ" เมื่อเขาย้ายในลักษณะที่คุกคาม พระมหากษัตริย์ของฝ่ายตรงข้ามกับการจับภาพ (และพระมหากษัตริย์มีความหมายของการหลบหนี) ฝ่ายตรงข้ามจะต้องได้รับพระมหากษัตริย์ออกจากการตรวจสอบทันที
- ก่อให้เกิดปัญหา หมากรุกเป็นปัญหาการค้นหาโดยการระบุพื้นที่ของรัฐสถานะเริ่มต้นเป้าหมายการดำเนินการค่าใช้จ่ายในเส้นทาง
- สร้างต้นไม้ค้นหา
- ปัญหาที่อาจเกิดขึ้น
- จะเป็นการดีที่สร้างต้นไม้ค้นหาทั้งหมดทางลงไปทุกใบและใช้มินิแมกซ์ ใช้การตัดแต่งกิ่งα-βเพื่อลดต้นไม้ค้นหา
- ในความเป็นจริงต้นไม้ค้นหาอาจจะมีขนาดใหญ่เกินกว่าที่จะสร้าง
- แทนการสร้างต้นไม้ที่สมบูรณ์หยุดที่จุดหนึ่งและประเมินคุณภาพของโหนดโดยใช้ฟังก์ชั่นการประเมินผล
การตัดสินใจแบบ Real-Time
- โดยประมาณ (และแน่นอน) การแก้ปัญหา
- ใช้ฟังก์ชั่นการประเมินผลการแก้ปัญหา
- กำหนดของสถานะ (หรือขั้วกลาง) ฟังก์ชั่นการประเมินผลตอบแทนประมาณการของยูทิลิตี้ที่คาดหวังของเกมที่
- ควรจะรวดเร็วในการคำนวณ
- Ex: ฟังก์ชั่นการประเมินผลง่ายสำหรับการหมากรุก
Pawn: 1 point
Knight/bishop: 3 points
Rook: 5 points
Queen: 9 points
สรุปผลคะแนนของทุกชิ้นบนกระดาน
ฟังก์ชั่นการประเมินผลที่สูงขึ้นอาจจะยัง
มองไปที่ความสัมพันธ์ระหว่างตำแหน่งในหมู่ชิ้น
- ในการตัดสินใจแบบ real-time ใช้มินิแมกซ์ที่มีการตัดแต่งกิ่งα-βกับสองการปรับเปลี่ยน
-Cut ออกต้นไม้ค้นหาที่ขีด จำกัด ระดับความลึกคงที่
-ฟังก์ชั่นการประเมินผลการใช้งานที่จะประเมินยูทิลิตี้ของสถานะ
- ตัดควรจะนำมาใช้กับนิ่ง (ไม่สำคัญ) รัฐ
เป็นเกมส์ผลรวมเป็นศูนย์ เนื่องจากผลรวมนี้คือการรวมความสำเร็จ ชนะพร้อมกันไม่ได้
1. ขั้นตอนวิธีแบบค่าน้อยสุด-มากสุด minimax algorithm จุด root node แทนผู้เล่นแรกๆ และจุดโหนดลูกแทนผู้เล่นฝ่ายตรงข้าม จุดปลายสุดจะระบุคะแนน เราต้องหาการเล่นวิธีที่ดีดีที่สุดของผู้เล่นคนแรกดังนั้น จึงเลือกคะแนนสูงสุดต่อจุดของจุดต่อลูกๆๆของมัน ส่วนที่จุดต่อของผู้เล่นฝั่งตรงข้ามจะเลือกคะแนนสูงสุดของจุดต่อลูกๆมัน ส่วนจุดต่อฝั่งตรงข้ามจะเลือกคะแนนต่ำสุดของจุดลูกๆของมัน สำหรับจุดต่อที่น้อยที่สุดMIN คะแนนเริ่มแรกก่อนการเปรียบเทียบ จะเท่ากับ +infinityและลดลงเรื่อยๆเมื่อโปรแกรมทำงานต่อไป ส่วนจุดต่อมากที่สุด(MAX)คะแนนจะเริ่มที่-infinityและเพิ่มขึ้นเรื่อยๆ แผนถูมิต้นไม้ขนาดใหญ่จนต้องกำหนดขอบเขตล่วงหน้า
1. ขั้นตอนวิธีแบบค่าน้อยสุด-มากสุด minimax algorithm จุด root node แทนผู้เล่นแรกๆ และจุดโหนดลูกแทนผู้เล่นฝ่ายตรงข้าม จุดปลายสุดจะระบุคะแนน เราต้องหาการเล่นวิธีที่ดีดีที่สุดของผู้เล่นคนแรกดังนั้น จึงเลือกคะแนนสูงสุดต่อจุดของจุดต่อลูกๆๆของมัน ส่วนที่จุดต่อของผู้เล่นฝั่งตรงข้ามจะเลือกคะแนนสูงสุดของจุดต่อลูกๆมัน ส่วนจุดต่อฝั่งตรงข้ามจะเลือกคะแนนต่ำสุดของจุดลูกๆของมัน สำหรับจุดต่อที่น้อยที่สุดMIN คะแนนเริ่มแรกก่อนการเปรียบเทียบ จะเท่ากับ +infinityและลดลงเรื่อยๆเมื่อโปรแกรมทำงานต่อไป ส่วนจุดต่อมากที่สุด(MAX)คะแนนจะเริ่มที่-infinityและเพิ่มขึ้นเรื่อยๆ แผนถูมิต้นไม้ขนาดใหญ่จนต้องกำหนดขอบเขตล่วงหน้า


Constraint Satisfaction Problems (ความพึงพอใจของปัญหาข้อจำกัด)
- ค้นหาปัญหามาตรฐาน:
-สถานะ,เป้าหมาย,การกระทำ,ฟังก์ชั่นการแก้ปัญหาที่มีโดเมนที่เฉพาะเจาะจง
- CSP:
-เป้าหมายการดำเนินการฟังก์ชั่นการแก้ปัญหาที่มีโดเมนที่เฉพาะเจาะจง
-สถานะเป้าหมายการดำเนินการเป็นไปตามมาตรฐานการแสดง
-ขั้นตอนวิธีการค้นหาสามารถใช้ประโยชน์จากโครงสร้างของรัฐและใช้งานทั่วไปมากกว่าการวิเคราะห์พฤติกรรมปัญหาที่เฉพาะเจาะจง
-สถานะจะถูกกำหนดโดยตัวแปร Xi ด้วยค่าจากDi
-ชุดของข้อจำกัด ที่อนุญาตระบุรวมกันของค่าสำหรับย่อยของตัวแปร
-วิธีการแก้ปัญหาให้กับ CSP เป็นรัฐที่ตอบสนองข้อ จำกัด ทั้งหมด
-อัลกอริทึมที่มีประโยชน์ช่วยให้วัตถุประสงค์ทั่วไปมีอำนาจมากขึ้นขั้นตอนวิธีการค้นหากว่ามาตรฐาน

การระบายสีแผนที่ให้ใช้สีที่น้อยที่สุดแสดงแผนที่
- ตัวแปร:WA, NT, Q,NSW, V, SA, T
- ขอบเขตที่สนใจ:Di = {สีแดง, สีเขียว, สีฟ้า}
- ข้อจำกัด:ภูมิภาคที่อยู่ติดกัน ต้องมีที่แตกต่างกัน สีเช่น WA ≠ NT
- วิธีการแก้ปัญหา:มีการมอบหมายงานที่สมบูรณ์และสอดคล้องกัน
- เสร็จสมบูรณ์: ตัวแปรทั้งหมดที่ได้รับมอบหมายค่า
- สอดคล้อง: ตอบสนองการกำหนดข้อจำกัด
Constraint graph
- Binary CSP: แต่ละข้อจำกัดที่เกี่ยวข้องกับสองตัวแปร
- Constraint graph: โหนดเป็นตัวแปรโค้งที่มีข้อจำกัด
ชนิดของข้อจำกัด
Unary constraints: ที่เกี่ยวข้องกับเอกตัวแปรเดียว
e.g., SA ≠ green
Binary constraints :-ข้อจำกัดเกี่ยวข้องกับคู่ของตัวแปร
e.g., SA ≠ WA
Higher-order: ข้อจำกัดที่เกี่ยวข้องกับมากกว่า3ตัวแปรขึ้นไป
ปัญหาที่ได้รับมอบหมายReal-world CSPs
=เช่นสิ่งที่สอนในชั้นเรียน
ปัญหา timetabling
=เช่น ระดับที่จะถูกนำเสนอเมื่อใดและที่ไหน
- การจัดตารางเวลาการขนส่ง
- การตั้งเวลาโรงงาน
- ขอให้สังเกตว่าปัญหาที่แท้จริงของโลกจำนวนมากที่เกี่ยวข้องกับมูลค่าที่แท้จริงตัวแปร
ค้นหาสูตรมาตรฐาน (เพิ่มขึ้น)Standard search formulation (incremental)
วิธีธรรมดาในการค้นหา
สถานะจะถูกกำหนดโดยค่าที่ได้รับมอบหมายเพื่อให้ห่างไกล
สถานะจะถูกกำหนดโดยค่าที่ได้รับมอบหมายเพื่อให้ห่างไกล
- สถานะเริ่มต้น: การกำหนดที่ว่างเปล่า {}
- ฟังก์ชั่นตัวตายตัวแทน (การกระทำ): กำหนดค่าให้ตัวแปรที่ไม่ได้กำหนดว่าไม่ขัดแย้งกับที่ได้รับมอบหมายในปัจจุบัน
-->ล้มเหลวถ้าไม่มีการกำหนดตามกฎ
- การทดสอบเป้าหมาย: การกำหนดปัจจุบันเสร็จสมบูรณ์
- ค่าใช้จ่ายในเส้นทาง: ค่าใช้จ่ายคงที่ (เช่น 1) สำหรับทุกขั้นตอนนี้จะเหมือนกันสำหรับ CSPs ทั้งหมด
วิธีการแก้ปัญหาทุกคนจะปรากฏขึ้นที่ระดับความลึก n กับตัวแปร n
-->ใช้การค้นหาความลึกแรก
ย้อนรอยการค้นหา (Backtracking search)
- ค้นหาความลึกเป็นครั้งแรกสำหรับ CSPs กับการกำหนดตัวแปรเดียวที่เรียกว่าการค้นหาย้อนรอย(backtracking search)
- เลือกค่าตัวแปรหนึ่งที่เวลาและย้อนรอยเมื่อตัวแปรมีค่าไม่เหลือทางกฎหมายที่จะกำหนด
- ค้นหา backtracking เป็นอัลกอริทึมไม่รู้ขั้นพื้นฐานสำหรับ CSPs


ย้อนรอยการปรับปรุงประสิทธิภาพ(Improving backtracking efficiency)
- วิธีการใช้งานทั่วไปมีความเร็วมากในการรับ:
- ซึ่งตัวแปรควรจะกำหนดต่อไปหรือไม่
- ในสิ่งที่เรียงลำดับตามค่าที่พยายาม?
- เราสามารถตรวจสอบความล้มเหลวที่หลีกเลี่ยงไม่ได้ในช่วงต้น?

ตัวแปรที่จำกัดมากที่สุด
ตัวแปรที่จำกัดมากที่สุด:เลือกตัวแปรที่มีค่าน้อยที่สุดตามกฎหมายที่
-a.k.a. ค่าขั้นต่ำที่เหลืออยู่ (MRV) การแก้ปัญหา
- หากมีตัวแปร X กับค่าศูนย์ตามกฎหมายที่เหลือ แก้ปัญหา MRV จะเลือก X และความล้มเหลวที่จะถูกตรวจพบ ทันทีที่หลีกเลี่ยงการค้นหาจุดหมายผ่านอื่น ๆ ตัวแปรซึ่งท้ายที่สุดก็จะล้มเหลวต่อไป
- ส่วนใหญ่ constraining ตัวแปร (หรือปริญญาแก้ปัญหา)
- เลือกตัวแปรที่มีข้อ จำกัด มากที่สุดในตัวแปรที่เหลือ
- พยายามที่จะลดปัจจัยที่แตกแขนงเกี่ยวกับทางเลือกในอนาคต
-จะมีประโยชน์เป็นผูกเบรกหลัง MRV แก้ปัญหา
ค่า constraining น้อย(Least constraining value)
Given ตัวแปรเลือกค่า constraining น้อย:- the หนึ่งที่ออกกฎทางเลือกน้อยที่สุดสำหรับตัวแปรที่เหลือ
It พยายามที่จะออกจากความยืดหยุ่นสูงสุดสำหรับการกำหนดตัวแปรที่ตามมา
การตรวจสอบไปข้างหน้า(Forward checking)
เมื่อใดก็ตามที่ตัวแปร X ที่มีการกำหนดขั้นตอนการตรวจสอบไปข้างหน้ามีลักษณะที่แต่ละ Y ตัวแปรที่ไม่ได้กำหนดที่เชื่อมต่อกับ X โดยข้อ จำกัด และลบจากY’s domainค่าใด ๆ ที่ไม่สอดคล้องกับค่าที่เลือกสำหรับปX.

การตรวจสอบไปข้างหน้า(Forward checking)
ความคิด:
- รูปที่1
- ติดตามเหลือค่าตามกฎสำหรับตัวแปรที่ไม่ได้กำหนด
- ยุติ (และ backtrack) ค้นหาเมื่อตัวแปรใดที่มีทางและค่าตามกฎ
- รูปที่2
- ติดตามเหลือค่าตามกฎสำหรับตัวแปรที่ไม่ได้กำหนด
- ยุติ (และ backtrack) ค้นหาเมื่อตัวแปรใดที่มีทางและค่าตามกฎ
- รูปที่3
- ติดตามเหลือค่าตามกฎสำหรับตัวแปรที่ไม่ได้กำหนด
- ยุติ (และ backtrack) ค้นหาเมื่อตัวแปรใดที่มีทางและค่าตามกฎ
- รูปที่4
- ติดตามเหลือค่าตามกฎสำหรับตัวแปรที่ไม่ได้กำหนด
- ยุติ (และ backtrack) ค้นหาเมื่อตัวแปรใดที่มีทางและค่าตามกฎ

- รูปที่5
- เมื่อเทียบกับไม่มีการตรวจสอบไปข้างหน้า: ตรวจพบปัญหาหลังจากที่ขั้นตอนที่5ได้รับมอบหมาย

การขยายพันธุ์อย่างจำกัด(Constraint propagation)
- การตรวจสอบการส่งต่อแพร่กระจายข้อมูลจากได้รับมอบหมายให้ตัวแปรที่ไม่ได้กำหนด แต่ไม่ได้ให้ตรวจสอบเริ่มต้นสำหรับความล้มเหลวทั้งหมด:
- NT และ SA ไม่สามารถทั้งเป็นสีฟ้า!
- การขยายพันธุ์อย่างจำกัด(Constraint propagation) ซ้ำบังคับใช้ข้อจำกัดในประเทศ มันแพร่กระจายผลกระทบของข้อจำกัด ในตัวแปรหนึ่งบนตัวแปรอื่น ๆ
Arc consistency(สอดคล้อง)
- รูปแบบที่ง่ายของการขยายพันธุ์ที่ทำให้โค้งแต่ละที่สอดคล้อง (consistent)กัน
- X--> Y ถ้ามีความสอดคล้อง
- สำหรับทุกค่า x ของ X มีบาง y ที่ได้รับอนุญาต
- การตรวจสอบความArc consistency ต้องใช้ซ้ำ ๆ จนกระทั่งไม่มีความไม่สอดคล้องกันมากขึ้นยังคงอยู่
- ถ้า x สูญเสียค่าใกล้เคียงของ X จะต้องมีการเดินทาง
- เช่นเมื่อ V สูญเสียค่าจะต้องตรวจสอบค่าของNSW และ SA’s จากนั้นจะต้องตรวจสอบค่าของNSW’s and SA’s และอื่น ๆ
Classes of Search
| Class | Name | Operation |
| ไม่รู้เส้นทางใด | Depth-First Breadth-First |
ระบบการตรวจสอบข้อเท็จจริงของต้นไม้ ทั้งค้นหาจนกว่าจะพบเป้าหมาย |
| รู้เส้นทางเส้นทาง | Greedy Best- First | ใช้มาตรการแก้ปัญหาของความดีของสถานะ เช่น ระยะทางประมาณเป้าหมาย |
| ไม่รู้ความเหมาะสม | UniformCost | ใช้เส้นทาง "ความยาว" วัดพบ "สั้น" เส้นทาง |
| รู้ความเหมาะสม | A* | ใช้เส้นทาง"ความยาว"
มาตรการและ การแก้ปัญหาพบเส้นทาง"สั้น" |

Uninformed (ไม่รู้) VS. Informed (รู้)
- Uninformed search :(หรือการค้นหาแบบตาบอด): ไม่มีเพิ่มเติมข้อมูลเกี่ยวกับสถานะเกินกว่าที่ระบุไว้ในคำนิยามปัญหา
- Informed search :(หรือการค้นหาที่ Heuristicการค้นหาที่เลือกคำตอบที่เหมาะสมกับการค้นหาเท่านั้นแต่อาจจะไม่ใช่คำตอบที่ดีที่สุด): ใช้ problem- 7? ค้นหาแจ้ง (เทียบกับการแก้ปัญหาการค้นหา): ใช้ความรู้เฉพาะปัญหาที่นอกเหนือจากความหมายของปัญหาของตัวเอง


Informed (Heuristic) Search
- บางขั้นตอนวิธีการค้นหาที่ใช้heuristic functions.
- heuristic functionsอาจจะช่วยเป็นแนวทางในการค้นหาและเพิ่มความเร็วอย่างน้อยโดยเฉลี่ยกระบวนการในการหาที่เป้าหมาย
- การประเมินผลการใช้ฟังก์ชัน f (s) ซึ่งประมาณการระยะทางไปยังเป้าหมาย
- ขยายโหนดที่มีลักษณะที่ดีที่สุด (มีแนวโน้มมากที่สุด)ในขณะที่คนที่มีต่ำสุด f (s)
- เราจะหารือสองวิธี:
- Greedy best-first search
- A* search
Greedy Best-First Search
- ขยายโหนดที่ปรากฏขึ้นใกล้เคียงกับเป้าหมาย
- เลือกเส้นทางที่ดีที่สุดที่ดูจากโหนดปัจจุบัน S เพื่อเป้าหมาย
- f (s) = h (s) h (s): ประเมินค่าใช้จ่ายของเส้นทางถูกที่สุดจากโหนดเพื่อเป้าหมาย
- h (เป้าหมาย) = 0



- วิธีการแก้ปัญหา:A-C-O-N-E-X เสียค่าใช้จ่าย 86
- ทางออกที่ดีที่สุด: A-S-P-X เสียค่าใช้จ่าย 80
- วิธีการแก้ปัญหาที่พบโดยโลภค้นหาที่ดีที่สุดอาจจะเป็นครั้งแรกไม่เหมาะสม
A* Search
- ขยายโหนดที่ปรากฏอยู่บนเส้นทางที่ดีที่สุดจากจุดเริ่มต้นไปสู่เป้าหมาย
- เลือกเส้นทางที่ดีที่สุดที่ดูจากจุดเริ่มต้นไปสู่เป้าหมาย
- f (s) = g (s) + h (s)
g (s): ค่าใช้จ่ายของเส้นทางที่ถูกที่สุดตั้งแต่ต้นจน s
h (s): ประเมินค่าใช้จ่ายของเส้นทางถูกที่สุดจาก s ไปโหนดเป้าหมาย
- h (เป้าหมาย) = 0



- ในตัวอย่างของเรา A * พบทางออกที่ดีที่สุด:A-S-P-X (เสียค่าใช้จ่าย 80)
- นี้ไม่ได้เกิดอุบัติเหตุ ในความเป็นจริง A * จะเสมอหาทางออกที่ดีที่สุดทุกครั้งที่เขา) ตอบสนองเงื่อนไขบางอย่าง
Admissibility
ฟังก์ชั่นการแก้ปัญหา h (s) เป็นที่ยอมรับ (หรือในแง่ดี) ถ้ามันไม่เคย overestimates ค่าใช้จ่ายไปที่เป้าหมายA* Search
- A* = สมบูรณ์ที่สุด,ดีที่สุด
- A * จะเสร็จสมบูรณ์และที่ดีที่สุดที่ได้รับ h (s) ตอบสนองเงื่อนไขบางประการ
- เงื่อนไขอะไร?--> h (s) เป็นที่ยอมรับ
- ดังนั้น เป็นปัญหาหรือไม่? -->หน่วยความจำ
หน่วยความจำขอบเขตในการค้นหาแบบHeuristic
- A * ความต้องการในปริมาณที่ชี้แจงของหน่วยความจำ
- การแก้ไข: การใช้หน่วยความจำขอบเขตการค้นหาแก้ปัญหา
ซ้ำที่ดีที่สุดครั้งแรกที่การค้นหา (BFS)
ซ้ำ-ลึก * A (IDA *)
หน่วยความจำแบบย่อขอบเขต A * (SMA *)
ซ้ำที่ดีที่สุดครั้งแรกที่การค้นหา (RBFS)
- หนึ่งที่ไม่สามารถให้ขึ้นใจของพวกเขา
- คล้ายกับ DFS แต่แทนที่จะดำเนินการต่อไปอย่างไม่มีกำหนดลงเส้นทางปัจจุบัน RBFS ติดตามมูลค่าของเส้นทางเลือกที่ดีที่สุดที่มีอยู่จากบรรพบุรุษใด ๆ ของโหนดปัจจุบัน ถ้าโหนดปัจจุบันเกินกว่านี้วงเงินที่เรียกซ้ำคลายกลับไปที่ทางเลือกเส้นทาง ในฐานะที่เป็นเรียกซ้ำคลาย, RBFS แทนที่ค่าของแต่ละโหนดไปตามเส้นทางที่ดีที่สุดมูลค่าของโหนดลูก






- ที่ดีที่สุดถ้า h เป็นที่ยอมรับ
- การเปลี่ยนแปลงและยังคงมีหน่วยความจำน้อยจึงลำบากในการฟื้นฟูโหนดที่มากเกินไป
- ประหยัดมากเกินไปเกี่ยวกับหน่วยความจำที่มันไม่มีประสิทธิภาพ
IDA*
- ซ้ำ-ลึก * A (IDA *)
- คล้ายกับการค้นหาลึกซ้ำมาตรฐาน แต่ใช้f ค่าใช้จ่าย (g + h) เป็นทางลัด (แทนของความลึก); ที่ซ้ำกัน, ตัดเป็นค่าใช้จ่าย f เล็กที่สุดของโหนดใด ๆ ที่เกินตัดทวนก่อนหน้านี้
Simplified Memory-Bounded A* (SMA*)
- ขยายที่ดีที่สุด (ต่ำสุด f) โหนดจนกว่าหน่วยความจำเต็ม
- เพิ่มโหนดใหม่ในการค้นหาต้นไม้โดยวางโหนดเก่า มักจะลดลงที่เลวร้ายที่สุด (f สูงสุด) อย่างใดอย่างหนึ่ง
- เมื่อวางโหนดสำรองค่า F ไปยังparent ด้วยวิธีนี้ancestor ของทรีย่อย(subtree) ไม่รู้ที่มีคุณภาพของเส้นทางที่ดีที่สุดในทรีย่อยว่า
- เพิ่มทรีย่อย(subtree)ใหม่ลืมเฉพาะเมื่อเส้นทางอื่น ๆ ได้รับการแสดงที่จะดูแย่ลง
การค้นหาแบบกำหนดทิศทาง
เป็นการค้นหาแบบที่เริ่มต้นการสำวจจากโหนดหนึ่งไปยังอีกโหนดหนึ่งอาศัยทิศทางเป็นตัวกำหนดการค้นหา ไม่มีข้อมูลอะไรมาเสริมการตัดสินใจ คือการหยิบข้อมูลมาตรวจสอบในขั้นต่อไป ไม่ต้องอาศัยข้อมูลใดๆทั้งสิ้น ตัวอย่าง Depth First Search ,Breadth First Search
การค้นหาDepth First Search
เป้นการค้นหาแบบลึกก่อน กำหนดทิศทางจากรูปโครงสร้างต้นไม้ เริ่มจากRoot เดินลงมาที่ลึกสุดTerminal Node ให้ย้อนขึ้นไปที่กิ่ง แยกต่ำสุดของกิ่งเดียวกัน และยังไม่ทำการสำรวจแล้วทำการสำรวจโหนดในกิ่งนั้น ถ้าพบโหนดที่ต้องการการค้นหาก็สิ้นสุด ถ้าไม่พบก็สำรวจจนถึงปลายทาง ถ้าไม่พบให้ย้อนขึ้นมายังกิ่งแยกต่ำสุดที่ยังไม่สำรวจถัดไปแล้วทำการสำรวจโหนดบนกิ่งแยกนั้น ทำสลับกับไปเรื่อยๆจนพบโหนดที่ต้องการหาหรือสำรวจให้ครบทุกโหนด

เมื่อการค้นหาในกิ่งแรกมาถึงโหนดปลายทาง คือ 4 การค้นหาจะย้ายไปที่โหนดต่ำสุดที่มีกิ่งแยกไม่มีการสำรวจ ในที่นี้คือกิ่งโหนด 3 ให้ทำการสำรวจโหนด 5 ซึ่งเป็นโหนดปลายทาง จากนั้นย้อนไปจุดต่ำสุดในตำแหน่งเดียวกันที่มีกิ่งแยกและกิ่งแยกนั้นไม่มีการสำรวจ ในที่นี้โหนด2 ทำการสำรวจโหนด 6 ทำเช่นนี้ครบทุกโหนด หรือพบโหนดที่ต้องการหาแบบลึกก่อน เมื่อสำรวจโหนดในกิ่งใดกิ่งหนึ่ง ที่เริ่มต้นจากโหนดรากลงมา เราต้องบันทึกว่าโหนดใดบ้างมีกิ่งแยกออกมา
การค้นหาBreadth First Search
เป็นการกำหนดทิศทางการค้นหาที่ทำการสำรวจที่ละระดับของโครงสร้างต้นไม้ ดดยเริ่มจากโหนดรากแล้วลงมาที่ระดับ1จากซ้ายไปขวา จนกว่าจะพบโหนดที่ต้องการ หรือจนครบทุกโหนด เป้นหมายเลขที่กำกับบนโหนด

จะอาศัยการจัดการโครงสร้างข้อมูลแบบคิวมาช่วย เช่นกัน ด้วยวิธีการเช่นเดียวกับการค้นหาแบบลึกก่อน คือให้เริ่มต้นสำรวจที่โหนดเริ่มต้น แล้วนำโหนดที่ข้างเคียงเก็บไว้ในคิว เมื่อสำรวจโหนดเริ่มต้นจนเสร็จ ให้นำข้อมูลในคิวออกมาสำรวจ นำโหนดข้างเคียงที่ไม่ได้สำรวจและไม่ได้อยู่ในคิวใส่ในคิว ทำจนพบโหนดที่ต้องการหรือเมื่อสำรวจครบทุกโหนด สำหรับโหนดข้างเคียงในที่นี้หมายถึงโหนดที่มีเส้นเชื่อม เชื่อมกับโหนดที่กำลังสำรวจหรือกล่าวอีกนัยหนึ่ง คือ โหนดที่อยู่ติดกันและมีทางเดินเชื่อมหากัน
การค้นหาแบบฮิวริสติก
ความแตกต่างระหว่างการค้นหาข้อมูลธรรมดา และ การค้นหาข้อมูลแบบฮิวริสติก(Heuristic Search) การค้นหาแบธรรมดาจะเป็นการตรวจสอบข้อมูลจนครบ ถ้าข้อมูลไม่ใหญ่มาก การค้นหาแบบนี้จะให้คำตอบที่ถูกต้องเสมอ แต่ในบางครั้งข้อมูลมีขนาดใหญ่มาก การตรวจสอบต้องทำหลายล้านครั้ง ซึ่งทำให้การเปรียบเทียบข้อมูลทุกตัวเพื่อหาคำตอบที่เป็นไปไม่ได้ ลักษณะของปัยหาแบบนี้ เช่น การหาทางที่สั้นที่สุดเราจะต้องเปรียบเทียบเส้นทาง 99! ครั้ง หรือ (n-1)! เมื่อ n คือจำนวนเมืองซึ่งต้องการเปรียบเทียบจำนวนที่ไม่อาจเปรียบเทียบให้เสร็จได้ ดังนั้นจะตอบคำถามว่าเส้นที่สั้นที่สุดคือเส้นทางใด จะยากมากและอาจหาไม่ได้เลยก็ได้ ดังนั้นการแก้ปัญหาต้องอาศัยวิธีการฮิวริสติก วิธีการนี้เลือกคำตอบที่เหมาะสมให้กับการค้นหาเท่านั้น แต่ไม่ได้คำตอบที่ดีที่สุด
เครื่องมือช่วยค้นหาฮิวริสติก คือ ฮิวริสติกฟังชัน
Heuristic Functionทำหน้าที่วัดขนาดความเป็นไปได้ในการแก้ปัญหา เพื่อกำหนดทิศทางของการค้นหาคำตอบ หรือกล่าวอีกนัยหนึ่งคือ ฮิวริสติกฟังชันจะเป็นการบอกว่าสำรวจครั้งต่อไปจะเลือกสำรวจโหนดที่กิ่งใด โดยบอกขนาดของความเป็นไปได้ และขนาดความเป็นไปได้แสดงเป้นตัวเลข
การวัดความเป็นไปได้ในการแก้ปัญหา จะกระทำได้โดยพิจารณษถึงวิธีการ(Aspects)ต่างๆ ที่ใช้ในการแก้ปัญหา ณ สถานะหนึ่งว่า จะสามารถแก้ปัญหาได้ตามที่ต้องการหรือไม่ โดยกำหนดน้ำหนักที่ให้กับการแก้ปัญหาของแต่ละวิธี น้ำหนักเหล่านี้จะถูกแสดงด้วยตัวเลขที่กำกับไว้โหนดต่างๆ ในกระบวนการค้นหา และค่าเหล่านี้จะเป็นตัวที่ใช้ในการประมาณความเป็นไปได้ว่าเส้นทางผ่านโหนดนั้น มีความเป็นไปได้นำสู่หนทางการแก้ปัญหาได้มากน้อยแค่ไหน
เครื่องมือช่วยค้นหาฮิวริสติก คือ ฮิวริสติกฟังชัน
Heuristic Functionทำหน้าที่วัดขนาดความเป็นไปได้ในการแก้ปัญหา เพื่อกำหนดทิศทางของการค้นหาคำตอบ หรือกล่าวอีกนัยหนึ่งคือ ฮิวริสติกฟังชันจะเป็นการบอกว่าสำรวจครั้งต่อไปจะเลือกสำรวจโหนดที่กิ่งใด โดยบอกขนาดของความเป็นไปได้ และขนาดความเป็นไปได้แสดงเป้นตัวเลข
การวัดความเป็นไปได้ในการแก้ปัญหา จะกระทำได้โดยพิจารณษถึงวิธีการ(Aspects)ต่างๆ ที่ใช้ในการแก้ปัญหา ณ สถานะหนึ่งว่า จะสามารถแก้ปัญหาได้ตามที่ต้องการหรือไม่ โดยกำหนดน้ำหนักที่ให้กับการแก้ปัญหาของแต่ละวิธี น้ำหนักเหล่านี้จะถูกแสดงด้วยตัวเลขที่กำกับไว้โหนดต่างๆ ในกระบวนการค้นหา และค่าเหล่านี้จะเป็นตัวที่ใช้ในการประมาณความเป็นไปได้ว่าเส้นทางผ่านโหนดนั้น มีความเป็นไปได้นำสู่หนทางการแก้ปัญหาได้มากน้อยแค่ไหน
การค้นหาBest-first search
การค้นหาแบบเลือกโหนดที่ดีที่สุด (most promising) การทราบว่าโหนดใดดีที่สุดนี้สามารถทำได้โดยอาศัยฮิวริสติกฟังชั่น ฮิวริสติก ฟังชันนี้ทำหน้าที่เหมือนตัววัดผลกรีดีอัลกอริทึมGreedy Algorithm
เลือกโหนดที่ดีที่สุดก่อน อาศัยการวัดสถานะไปยังเป้าหมาย ดังนั้นการเลือกโหนดต้องเลือกโหนดที่มีค่าh ดีที่สุด
การค้นหาด้วยอัลกอริทึมA*
เลือกโหนดที่ใช้ดำเนินการต่อที่ดีที่สุด วิธีการเลือกโหนดที่ใช้ในการดำเนินการต่อ พิจารณาจากโหนดที่ดีที่สุด ความแตกต่างระหว่างA* กับฮิวริกฟังชั่น ฮิวริกฟังชั่น จะวัดจากโหนดราก(เริ่ม) โหนดปัจจุบัน(สถานะปัจจุบัน) แต่ค่าฮิวริสติก ฟังก์ชั่นA*จะเกิดการรวมค่า2ค่า คือ ค่าวัดจากสถานะปัจจุบันไปยังสถานะเริ่มต้น รวมค่าที่วัดจากสถานะปัจจุบัยนไปยังสถานะเป้าหมายถ้ากำหนดให้ตัวแปร fแทนค่าของฮิวริสติก ฟังชันของA* และg เป็นฟังชันที่ใช้วัดค่า(cost)จากสถานะเริ่มต้นจนถึงสถานะปัจจุบัน h' เป็นฟังชั่นที่ใช้วัดค่าจากสถานะปัจจุบันถึงสถานะเป้าหมาย
การค้นหาข้อมูลแบบ A*ของปัญหา 8-Puzzle ในการคำนวณค่าของ g คือการเปรียบเทียบสถานะปัจจุบัน กับสถานะเริ่มต้น และค่า h' คือการเปรียบเทียบสถานะปัจจุบันกับสถานะเป้าหมาย ซึ่งในการคำนวณค่าgและh'
การหาค่าของ g ทำได้โดยเปรียบเทียบสถานะปัจจุบันกับสถานะเริ่มต้น คือการนับว่าแต่ละช่องของตารางปัจจุบันห่างจากจุดเริ่มต้นไปกี่ช่อง เช่นที่ช่อง1ตารางทั้งสองไม่ห่างกัน ดังนั้นได้ค่า0 ที่ช่อง1ที่ช่อง2 สถานะปัจจุบันไม่มีค่าไม่คิด และเช่นกันที่ช่องที่3และ4ก็มีค่าเป็น0 เพราะทั้งสองตารางไม่ต่างกัน สำหรับตารางที่5 จะมีค่าเป็น1เพราะ8ห่างจากที่เคยอยู่ 1 ช่อง ทำเช่นนี้เรื่อยๆเราจะได้คำตอบช่องตารางต่างๆ ดังนี้
1=0,2=0,3=0,4=0,5=1,6=0,7=0,8=1,9=0รวม g=2
 |
| สถานะเริ่มต้น |
 |
| สถานะเป้าหมาย |
1=0,2=0,3=0,4=0,5=1,6=0,7=0,8=1,9=0รวม g=2
สำหรับค่าของ h'จะได้
1=1,2=0,3=0,4=1,5=1,6=0,7=0,8=1,9=0รวมh'=3 f=2+3=5
1=1,2=0,3=0,4=1,5=1,6=0,7=0,8=1,9=0รวมh'=3 f=2+3=5

ข้อสังเกต
1.เกี่ยวกับตัวอัลกอริทึม
- คำนึงถึงเส้นทางที่ดีที่สุดด้วย
- ทำอย่างไรให้ได้คำตอบนั้น กำหนดให้ g=0
- ถ้าต้องการให้ได้เส้นทางที่มีขั้นตอนน้อยที่สุด เราสามารถกำหนดให้ ค่าของโหนดไปยังโหนดลูกมีค่าคงที่(เท่ากับ 1)
2.เกี่ยวกับค่า h'และ h (ค่าจากโหนดถึงโหนดลูก)
- ถ้า h'เป็น perfect estimator ของh, A* algorithm กลายเป็นการเข้าหาเป้าหมายโดยไม่มีการค้นหา
- เมื่อ h'= ค่าที่ดีที่สุด ก็คือการหากำหนดระยะทางที่ใกล้ที่สุด
- เมื่อh'=0 การค้นหาจะถูกควบคุมโดยg
- ถ้าg=0อีก การค้นหาจะเป็นแบบ random
- ถ้าgเป็น1การค้นหาจะเป็น breadth-first
การแทนความรู้ (Knowledge Representation)
กำหนดปัญหา
หนึ่งวิธีการทั่วไปในการแก้ปัญหาในไอเพื่อลดปัญหาที่จะแก้ไขให้เป็นหนึ่งในค้นหากราฟ
การใช้วิธีการนี้เราจะต้องกำหนดปัญหาที่เกิดขึ้นโดยระบุ
การใช้วิธีการนี้เราจะต้องกำหนดปัญหาที่เกิดขึ้นโดยระบุ
- State space
- เริ่มต้นState
- เป้าหมาย
- การดำเนินการ
Stateแสดงทั้งหมด (และโดยเฉพาะอย่างยิ่งเท่านั้น)ด้านที่เกี่ยวข้องของปัญหาที่จะแก้ไขพื้นที่State
คือชุดของStateที่เป็นไปได้ทั้งหมด
เราถือว่าการกระทำที่มีกำหนดว่าเป็นเราทราบว่าหลังจากที่Stateกระทำที่เป็นดำเนินการ
นอกจากนี้เรายังคิดว่าการดำเนินการที่มีความต่อเนื่อง

กราฟที่1 กราฟแสดงถึงปัญหาที่เกิดขึ้น
กราฟที่2 การค้นหาจากต้นไม้ของกราฟ

initial state = คือสถานะเริ่มต้น
goal = เป้าหมา่ยที่อยากให้ตัวเลขมันเรียงกัน
กราฟแสดงถึงปัญหาที่เกิดขึ้น

ไปจาก A ถึง B โดยใช้ขั้นตอนน้อยที่สุดเท่าที่เป็นไปได้

ชั้นของการค้นหา

Breadth-First Search ตามแนวกว้าง

Depth-First Search ตามแนวลึก

ข้อเสียDepth-First Search
-เป็นวิธีที่ไม่ดี
-ไม่รับประกันว่าจะหยุด ถ้าต้นไม้มากมายก็ต้องค้นจากที่ลึกก่อน เพื่อแก้ไขปัญหานี้:Depth-Limited Search
Depth-Limited Search
- DFS ที่มีความลึกคงที่ โหนดที่ระดับความลึกไม่มีการสืบทอด
- อะไรคือสิ่งที่เหมาะสมcut-off depth d?
- ถ้า d มีขนาดเล็กเกินไปไม่อาจหาเป้าหมายได้
- ถ้า d มีขนาดใหญ่เกินไป: การทำงานพิเศษ
- สิ่งที่เกี่ยวกับการเริ่มต้นที่มีขนาดเล็กและให้ d เพิ่มขึ้น?
- ซ้ำลึกการค้นหา
Iterative Deepening Search
- ค้นหาลึกมากขึ้น
- DFS มีความลึกคงค่อยๆที่เพิ่มขึ้น
- มันไม่ซ้ำมากเกินไปในการทำงานหรือไม่
- ในต้นไม้เวลาถูกครอบงำโดยการค้นหาแนวลึกที่สุด(deepest search)
ประสิทธิภาพ
- สมบูรณ์: การประกันเพื่อหาทางแก้ปัญหาเมื่อในทางหนึ่งที่มีอยู่?
- เหมาะสมกับ: ทางออกที่ดีที่สุด?
- ซับซ้อนเวลา
- ซับซ้อนพื้นที่
เกณฑ์ BFS DFS
เสร็จสมบูรณ์? Yes Yes
(ถ้าไม่มีเส้นทางที่ไม่มีที่สิ้นสุด)
การเชื่อมโยงน้อยที่สุด? Yes No
(แต่ไม่จำเป็นต้องเป็นทางออกที่ดีที่สุด)
เวลา O(bd) O(bm)
พื้นที่ O(bd) O(bm)

กรณีเวลาที่เลวร้ายที่สุด
ในการค้นหา
- ปัจจัยที่แตกแขนง
- d: ความลึกของเป้าหมายตื้น
- m: ความลึกสูงสุดของต้นไม้ค้นหา (ดังนั้น d = เมตร BFS, d≤mใน DFS)
ในกรณีที่เลวร้ายที่สุดวิธีการค้นหาอาจจะจบลงมีการขยายตัวของสถานะ
- BFS: O (BD)
- DFS: O (พิพิธภัณฑ์)

BFS
- กรณีที่เลวร้ายที่สุดที่เกิดขึ้นเมื่อโหนดทั้งหมดที่ระดับความลึก d ได้รับการสร้างขึ้น แต่ไม่ขยายตัวเลย
- Q มีขนาด BD, ที่อยู่, ขนาดชี้แจงใน d
 |
DFS
- Q ถือที่ยังไม่ขยาย "พี่น้องsiblings" ของโหนดตามเส้นทางที่ได้รับการพิจารณา
- Q ถือไม่เกิน m(b-1)+1 = O(bm)
BFS Revisited
- การขยายตัว Node: A, B, C, E (เป้าหมาย)
- โซลูชั่นที่พบ: A-B-E (ค่าใช้จ่าย 100) - ไม่ดีที่สุด
- การแก้ไขปัญหานี้: การค้นหาเครื่องแบบค่าใช้จ่าย

Uniform-Cost Search การค้นหาแบบประหยัดต้นทุน
- ขยายโหนดที่มีค่าใช้จ่ายในเส้นทางที่ต่ำที่สุด (ใกล้เคียงกับเป้าหมาย)
- เหมือนกับ BFS หากค่าใช้จ่ายขั้นตอนทั้งหมดเท่ากัน

- การขยายตัว Node: A, C, D, E (เป้าหมาย)
- โซลูชั่นที่พบ: A-C-D-E (ต้นทุน 3) - ที่ดีที่สุด
- ที่ดีสำหรับค่าใช้จ่ายที่ไม่สม่ำเสมอ
Bidirectional Searchการค้นหาสองทิศทาง
- การค้นหาพร้อมกันสองคนคนหนึ่งไปข้างหน้าจากสถานะเริ่มต้นย้อนหลังจากเป้าหมายอื่น ๆ
- ประหยัดพื้นที่